Introduction
This documentation lists technical issues encountered during the development of lilyplayer and how they were taken care of (or not).
If you are interested in how the software extracts the keys to plays, when to play them, and how to overlay a cursor on top of the music sheet, have a look at this page instead
Issues with slowness of computing music data
When porting the software to webassembly, a performance issue got uncovered. Since lilyplayer is a music-playing software, it has real-time constraints, even though it only deals with "soft real-time", not hard real-time. When listening to the music, it was clear that the wasm version was too slow. The music was clearly played too slowly compared to the real deed.
However, the performance issue was only appearing on the wasm version, not the native one.
Since webassembly does not provide good tools for troubleshooting performance issues, the method to find out what was taking too slow was simply to manually log how long operations were taking. This was done using the old and reliable method of starting a chrono before, doing work, and stopping it once the work is done.
Turned out, the slowness was all in computing music data.
Difference in processing music between wasm and native
The software used for producing music out of midi events used to be librtmidi. When adding a webassembly version, a move to fluidsynth was made. The rationale behind was that using fluidsynth for native and webassembly seemed easier than getting librtmidi to work in a wasm context. As a bonus point, fluidsynth produces nicer quality output. Unfortunately, using fluidsynth for native and wasm is not done the same way.
Fluidsynth can output music to several backends like OSS, ALSA, SDL and a few more. These backends are ultimately where the operating system gets orders to send data to speakers. I'm simplifying a bit here. OSS and ALSA are linux APIs to do so and fluidsynth automatically picks a suitable backend based on the system it is running on.
In webassembly, the browser API for producing music is OpenAL ... which fluidsynth does not support. Consequently, to get music to the speaker, the wasm version of lilyplayer uses an intermediate step: it instructs fluidsynth to generate music data into a buffer and then pushes this buffer to openAL. On the native version, there is no intermediate buffer used, as fluidsynth directly outputs to the backend.
Using the timing method described above, we got that for each music_event (i.e. user plays some keys) generating music was taking around 250 microseconds (+/- 100 microseconds) on the native app, using a laptop produced in 2011 running linux, versus 70 milliseconds on firefox and 100-120 milliseconds for chrome on the same laptop. Thes numbers are not precise as at that moment I was only looking for broad numbers to find where the issue performance was, and not so much interested in making a good benchmark. A laptop from 2019 running macOS showed only slighty lower (around 20% lower) numbers for the wasm app.
The important thing to always keep in mind, is that when playing a song the maximum duration allowed to compute music data is decided by the music sheet. For example, let's say we are playing a song with tempo of 60 quarter note per minute, that is one quarter note per second, and the song consists only of four quarter notes in succession. In this case, we have a full second to compute music for one event, before the next event arrives. The faster paced the tempo and the music is, the less time for computation we have.
The data for Etude as dur - op25 - 01 from Chopin is as follow:
- 1060 times a maximum duration of 96ms to compute music
- 126 times, we can compute the music in at most 48ms.
- 5 times at most 24.038ms to compute music before hitting the milestone.
Seeing the computation times on firefox and chrome, we get that the software is just not efficient enough to play a fast-paced song like Chopin. Considering how fast computers are nowadays, and also the fact that the software had no issue with the native version, something had to be done.
A first experiment to know if using openAL was inherently slow, or if compiling to wasm was incurring too much overhead was to change the native program to do the same thing as the wasm one, that is use the intermediate buffer and output to openAL too.
The numbers I got were roughly about twice lower than wasm running on firefox, that is, the music computation was only twice as fast on native than wasm when using openAL. A computation with fluidsynth's usual backend takes roughly 250 - 300 microseconds, versus 35 milliseconds on native and twice as much on firefox. Wasm overhead compared to native is only a factor of 2, meaning I can't blame wasm for being too slow for my needs.
A more fine-grained measurement showed that the time was spent mostly into the fluidsynth method that computes the music data and puts it into this intermediate buffer, and not so much into openAL itself.
Optimisation #1: Compute music data less often
OpenAL and fluidsynth internals are nowhere near my core strengths, therefore the following was found via some trial and error method.
When playing music, the program was doing the following:
On keyboard event (i.e. when pressing or releasing piano keys):
For each key pressed:
- tell fluidsynth that key just got pressed
- ask fluidsynth to compute the new music data in a buffer
- send that buffer to openAL
For each key released:
- tell fluidsynth that key just got un-pressed
- ask fluidsynth to compute the new music data in a buffer
- send that buffer to openAL
Wait for the next event.
One attempt here was to restructure this code to only ask fluidsynth to compute the music data once per music event, in other words, changing the code to the following:
On keyboard event (i.e. when pressing or releasing piano keys):
For each key pressed:
- tell fluidsynth that key just got pressed
For each key released:
- tell fluidsynth that key just got un-pressed
ask fluidsynth to compute the new music data in a buffer
send that buffer to openAL
Wait for the next event.
An important thing to do when trying these possible optimisations is to always ensure that the software still works. A lot of my attempts resulted in having no music getting played at all, or sometimes being played but feeling jerky. I was concerned that this optimisation could lead to only hearing the music from the last key instead of all of them. Before looking into performance improvements, correctness need to be maintained.
On this attempt, if no measurable timing difference would appear, we would know that computing music is linear
to the number of key changes. If instead things would become about n times faster when there are n keys
pressed and released, it would mean filling the buffer takes the same amount of time regardless of the number
of key changes, and therefore should only be done as little times as strictly necessary.
Measuring this change showed that we were on the side of n times faster. This change alone was enough to
make music playable at the right speed. With this change, a music event takes about 12ms on firefox, and 20
on chrome. Of course the exact computation times change based on several factors, e.g. number of key changes
but also CPU thermal throtting or thread scheduling, of which I have little to no control over. Those numbers
here are only a ballpark figure, which leads to the next issue: music correctness.
After this optimisation, the timing for computation was as follow on firefox and chrome.
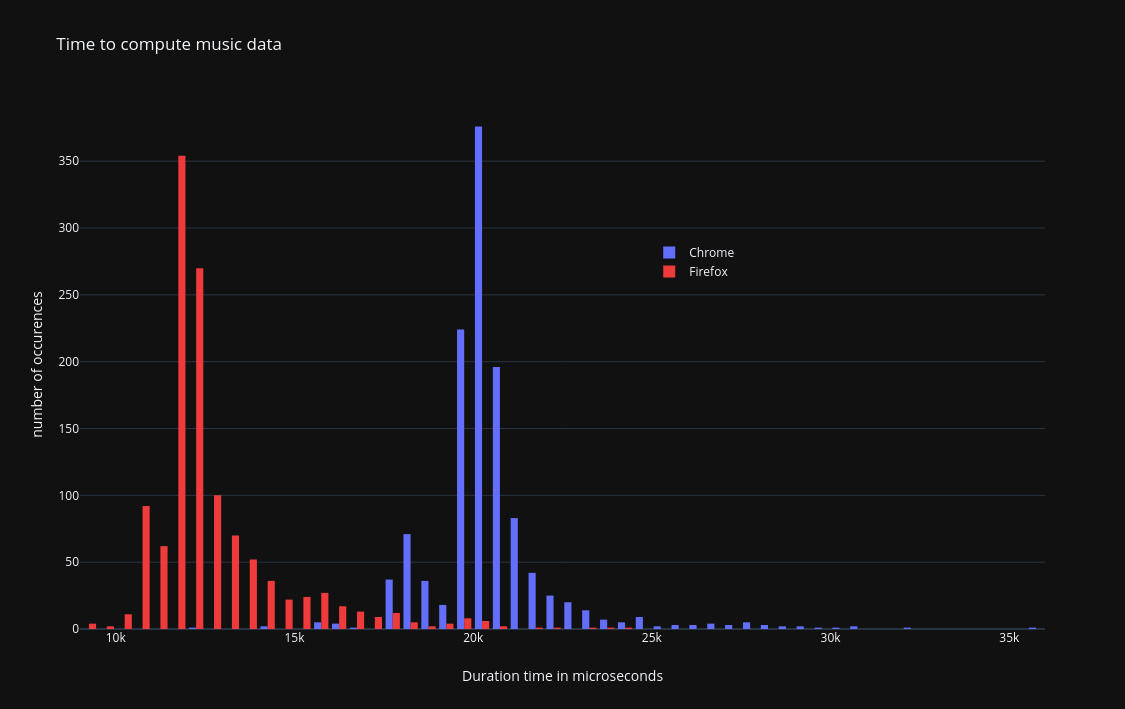
On this graph, each column represent a duration window of half a millisecond. We can see that firefox manages to compute the data most of time in less than 15 milliseconds. The most common duration being between 11.5 and 12 ms.
For chrome, the computation usually takes between 20 and 20.5 milliseconds.
| Durations in ms | min | average | stddev | max |
|---|---|---|---|---|
| firefox | 9.0 | 12.7 | 1.3 | 24.0 |
| chrome | 12.1 | 20.5 | 1.0 | 35.8 |
This graph was generated by playing Etude as dur -op25 - 01 on a 2011 laptop using firefox 102 and chromium
103 on linux with a kernel version 5.18.
Variance in waiting time between events:
As a consequence of the time it takes to compute music data there is a significant delay (of at least 9ms) between the moment some music shall be played, and when it actually is. This per-se is not so much of a problem. As a user this issue only manifests itself as a latency of a few milliseconds between clicking the play button, and the song actually starting. And since this latency is below 40milliseconds, a user will barely notice anything.
A bigger issue though, is that the compute time directly impacts the moment music is played, and this compute time varies for each event. The consequence is that events are therefore not played at the correct tempo.
Let's consider the following case:

This image is best viewed when right clicking on it and selecting "open image in new tab"
On this image, the two small rectangles on the first line represent the moment when the music should be played. The small red rectangles on the third line shows when they are actually played. Here we can visually see that the distance between the two "play music" boxes is not the same as the one between the two events.
The two music events should be played 96ms apart, but here they are played 96 - 35 + 12 = 73ms appart, a
whooping 23ms too early! 23 ms is a worst case based on the data empirically collected. One important point is
that since we have no control over this time discrepency, it is possible that one note is played too early and
the next one too late, or the opposite.
If we consider that the discrepency can go as high as 23ms, in the case of three quarter notes having to be played every 96ms, we can get a case of having the second one played 73ms after the first one instead of 96ms, and then the third one being played 119ms after the second one. This is not just playing the song too fast or too slow, it does not even respect the tempo!
Optimisation #2 (didn't work): precompute all the music buffers
An interesting observation that we got with the first optimisation was that the music computation time, which has to be fast, is mostly dominated by filling a buffer. And this buffer is used later on. Therefore, one "simple" optimisation here it to precompute the buffers of all the music events, and then when playing a music event, simply pass the relevant one to openAL. This would fix the issue of uncontrolled variance between music being played.
This failed for two reasons. The first one is due to startup load time. After the optimisation described
above, computing the buffer for a music event takes about 20ms on chrome. For a song like Etude as dur - op25 - 01 from Chopin - which is not even a long song - we are talking of 1209 music events. This multiplied
by approximately 20ms, means the loading time would be about 24 seconds. This is simply
unacceptable. Circumventing this issue could be done by having one thread computing the buffers running in
parallel to the one consuming them. Since the one consuming the event needs to wait between music_events, it
is pretty much guaranteed that it will never need to wait (except for the very first event) to get a buffer to
pass to openAL.
The second issue is related to memory usage. I capped the memory usage of the wasm
application at 120 MiB which I already think is a lot. Each buffer here take 44100 * sizeof(uint16_t) * 6
bytes which is slightly above half-megabyte. For the Chopin music sheet from above, this would mean using 2GiB
of memory just for the music data, which I consider unacceptable.
It would be possible to circumvent this by capping the number of buffers available to never run out of the
120MiB of memory (which includes the memory used by the app itself for everything else). On firefox, I could
use about 100 buffers before the app crashes with an out-of-memory errorm. It was approximately 80 on
chrome. Now comes the issue of finding out how many buffers can be allocated before the app crashes. One way
would be to simply keep allocating buffers, and catch the std::bad_alloc exception when reaching the
limit. Unfortunately the memory allocator on wasm doesn't throw std::bad_alloc, instead it simply
panics. This means that relying on this behaviour is not feasible. Ultimately, I decided not to try to get
this optimisation working as the benefits were not worth the cost when it would work anyway. It would allow
for about 2 seconds of pre computed music only. If a music sheet is fast paced enough to require music
computed in less than 20ms (the slowest time on chrome), this 2 second time window won't probably help much to
hide the slowness issue from the user, only delay it a bit.
Optimisation: precompute the following music buffer
In order to fix the variance issue, one has to ensure that the time between the moment music has to played, and when it is actually played is always the same. Ideally it has to also be minimal.
With the table we got after measuring computing time on chrome and firefox we see that the time to compute
music can cary by as much as 15ms for firefox and 23ms for chrome (max - min).
In other words, we can have the following situations:

The best way to view this image is to right click on it, and open in a new tab.
On this graph, we see that two red bars do not have the same length. The top one represent the time passed between the two events, in other words when the music should be played, whereas the second one shows how much time actually passed and when exactly the music was played.
On this example, the second event should be played exactly 96ms after the first one, but is actually played 113ms after. This is due to the fact that computing the music data for the second event took longer than computing the data for the first one, leading to playing the music too late. In the opposite case where computing the music for the first event would be slower than computing the data for the second, we would play the music too early.
The solution to avoid this problem relies on the fact that it usually takes less time to compute the music data than the time we have to wait before playing the next event. Remember that we deal with music sheets, not random events, we can always look ahead to know what is coming. The software takes advantage of this to pre-compute the next buffer that will be used. Consequently, as soon as an event arrives, the relevant music is already calculated and the software simply tells openAL to play that buffer, then the software uses its available timeslice to compute the data of the next event.
After this change, the graph of event processing looks like the following;

As can be seen, now the two red bars have the same lengths with the added benefit that they are much closer to each others. The difference in computation time of successive events are now absorbed in the waiting time, instead of impacting the moment the music gets played.
Conclusion:
A good way to write a small article on how to make things fast is to first:
- write something dog slow
- write it correctly
Note that doing the right thing from the get go doesn't provide for an opportunity to write such article. Might be a case of service recovery paradox :-)